You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named finance, finance contains two schemas named default and procurement.
You need to create a table named assets in the procurement schema, assets must contain the following columns:
• asset.id
• asset, type
• asset_name
How should you complete the SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.

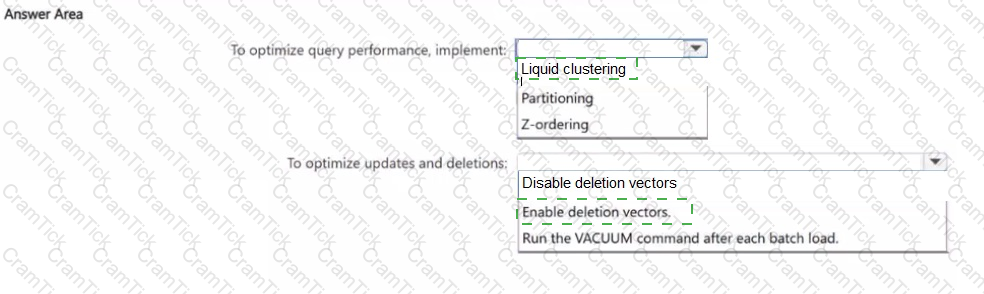
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Tabid.
Table! is written by batch jobs every hour and is queried frequently by filtering two columns named Customerld and EventDate.
You expect Table1 to grow significantly over time.
The rows in Table1 are frequently updated and deleted to support compliance requests.
You need to keep query performance consistent as Table1 grows. The solution must minimize update and deletion effort.
What should you include in the solution? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace that contains a job in Lakeflow Jobs named Job1.
Job! contains three tasks named Task1, Task2. and Task3.
If Task1 fails, Task2 and Task3 must be prevented from running. Successfully completed tasks must NOT rerun during recovery.
You need to configure Job1 to support controlled failure handling and recovery
What should you configure? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a Delta table named Orders.
You load the Orders table into an Apache Spark DataFrame named df.
You need to create a DataFrame that excludes rows where the order amount is null.
Solution: You run the following expression.
df.dropna(subset=["order_amount"])
Does this meet the goal?
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace that contains an all-purpose cluster named Cluster! You need to configure Cluster1 to meet the following requirements;
• The cluster must scale up automatically when workloads increase.
• The cluster must scale down automatically when workloads decrease.
The solution must minimize costs.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to recommend a pipeline that ingests files from cloud storage, performs cleansing and enrichment transformations, and writes created Delta tables for analytics. The solution must minimize development effort and provide built-in monitoring and automatic retries.
What should you include in the recommendation?
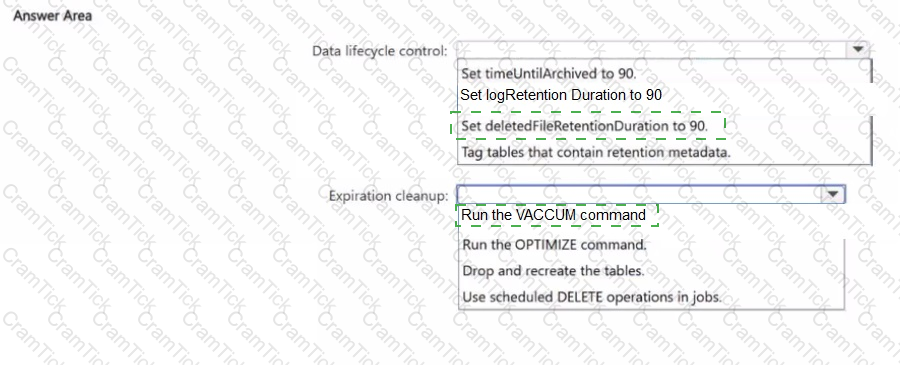
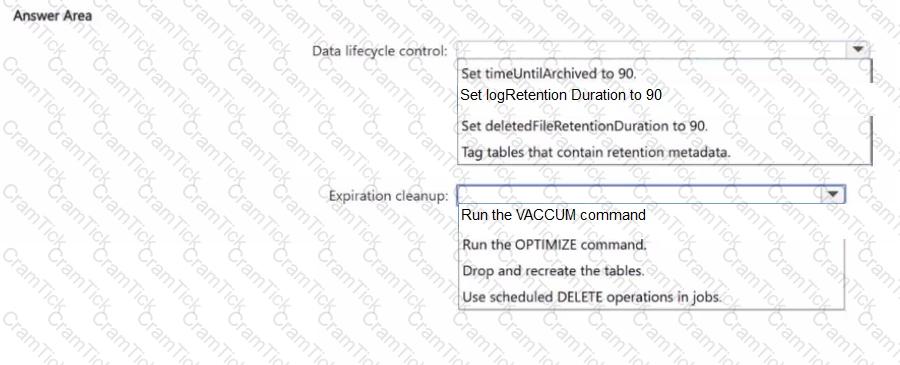
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to implement a data lifecycle and expiration solution that meets the following requirements
• Transaction logs and deleted data files that are older than 90 days must be removed from Delta tables to reclaim storage.
• All the tables must remain available for querying during the cleanup process.
• Administrative effort must be minimized
What should you do for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace that contains a Delta table named Table 1. Table 1 has accumulated obsolete files.
You need to reduce storage costs. The solution must preserve 30 days of time travel history. Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace that is enabled for Unity Catalog
You have a complex job named Job1 that contains eight tasks. Job! takes multiple hours to complete
During the last job run, the final task fails due to a transient issue.
You need to retry the last task without rerunning tasks that have already completed.
What should you do?




TESTED 21 Jun 2026