A Delta Live Table pipeline includes two datasets defined using streaming live table. Three datasets are defined against Delta Lake table sources using live table.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
What is the expected outcome after clicking Start to update the pipeline assuming previously unprocessed data exists and all definitions are valid?
A data analyst has a series of queries in a SQL program. The data analyst wants this program to run every day. They only want the final query in the program to run on Sundays. They ask for help from the data engineering team to complete this task.
Which of the following approaches could be used by the data engineering team to complete this task?
Which of the following describes when to use the CREATE STREAMING LIVE TABLE (formerly CREATE INCREMENTAL LIVE TABLE) syntax over the CREATE LIVE TABLE syntax when creating Delta Live Tables (DLT) tables using SQL?
A Databricks single-task workflow fails at the last task due to an error in a notebook. The data engineer fixes the mistake in the notebook. What should the data engineer do to rerun the workflow?
A data architect has determined that a table of the following format is necessary:

Which of the following code blocks uses SQL DDL commands to create an empty Delta table in the above format regardless of whether a table already exists with this name?

A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Which of the following approaches should be used to send the Databricks Job owner an email in the case that the Job fails?
In which of the following file formats is data from Delta Lake tables primarily stored?
Which of the following can be used to simplify and unify siloed data architectures that are specialized for specific use cases?
A data engineer needs to conduct Exploratory Data Analysis (EDA) on data residing in a database within the company’s custom-defined cloud network . The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
A global retail company sells products across multiple categories (e.g.. Electronics, Clothing) and regions (e.g.. North. South, East. West). The sales team has provided the data engineer with a PySpark dataframe named sales_df as below and the team wants the data engineer to analyze the sales data to help them make strategic decisions.
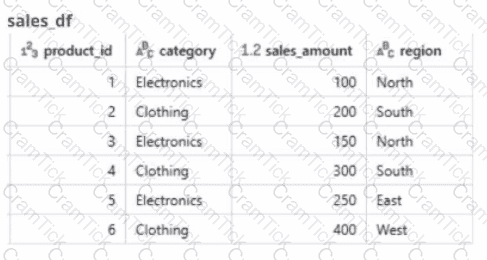
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
A data engineer is setting up access control in Unity Catalog and needs to ensure that a group of data analysts can query tables but not modify data.
Which permission should the data engineer grant to the data analysts?
A data engineer has joined an existing project and they see the following query in the project repository:
CREATE STREAMING LIVE TABLE loyal_customers AS
SELECT customer_id -
FROM STREAM(LIVE.customers)
WHERE loyalty_level = ' high ' ;
Which of the following describes why the STREAM function is included in the query?
A company is collaborating with a partner that does not use Databricks but needs access to a large historical dataset stored in Delta format. The data engineer needs to ensure that the partner can access the data securely, without the need for them to set up an account, and with read-only access.
How should the data be shared?
A data engineer is migrating pipeline tasks to reduce operational toil. The workspace uses Unity Catalog and is in a region that supports serverless. The engineer wants Databricks to auto-select instance types, manage scaling, apply Photon, and handle runtime upgrades automatically for job runs.
How should the data engineer meet this requirement while adhering to Databricks constraints?
A data engineer needs to combine sales data from an on-premises PostgreSQL database with customer data in Azure Synapse for a comprehensive report. The goal is to avoid data duplication and ensure up-to-date information
How should the data engineer achieve this using Databricks?
A data engineer is attempting to drop a Spark SQL table my_table. The data engineer wants to delete all table metadata and data.
They run the following command:
DROP TABLE IF EXISTS my_table
While the object no longer appears when they run SHOW TABLES, the data files still exist.
Which of the following describes why the data files still exist and the metadata files were deleted?
An organization plans to share a large dataset stored in a Databricks workspace on AWS with a partner organization whose Databricks workspace is hosted on Azure. The data engineer wants to minimize data transfer costs while ensuring secure and efficient data sharing.
Which strategy will reduce data egress costs associated with cross-cloud data sharing?
A data engineer is getting a partner organization up to speed with Databricks account. Both teams share some business use cases. The data engineer has to share some of your Unity-Catalog managed delta tables and the notebook jobs creating those tables with the partner organization.
How can the data engineer seamlessly share the required information?
A data engineer is using the following code block as part of a batch ingestion pipeline to read from a composable table:

Which of the following changes needs to be made so this code block will work when the transactions table is a stream source?
Which compute option should be chosen in a scenario where small-scale ad hoc Python scripts need to be run at high frequency and should wind down quickly after these queries have finished running?
A data engineer is running code in a Databricks Repo that is cloned from a central Git repository. A colleague of the data engineer informs them that changes have been made and synced to the central Git repository. The data engineer now needs to sync their Databricks Repo to get the changes from the central Git repository.
Which of the following Git operations does the data engineer need to run to accomplish this task?
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
A)
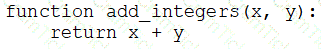
B)

C)
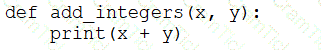
D)
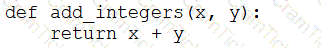
E)
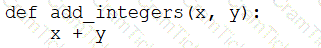
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
Which of the following commands will return the location of database customer360?
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command:

A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
A data engineer is standardizing repository layouts for multiple teams adopting Databricks Asset Bundles. The engineer wants to ensure every project has a single authoritative configuration file at the repository root that defines the bundle name, targets, workspace settings, permissions, and resource mappings (for jobs and pipelines).
Which strategy should the data engineer use to meet this goal?
A data engineer wants to schedule their Databricks SQL dashboard to refresh every hour, but they only want the associated SQL endpoint to be running when It is necessary. The dashboard has multiple queries on multiple datasets associated with it. The data that feeds the dashboard is automatically processed using a Databricks Job.
Which approach can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
A company uses Delta Sharing to collaborate with partners across different cloud providers and geographic regions. What will result in additional costs due to cross-region or egress fees?
Which method should a Data Engineer apply to ensure Workflows are being triggered on schedule?
A data engineer needs to create a table in Databricks using data from their organization ' s existing SQLite database. They run the following command:
CREATE TABLE jdbc_customer360
USING
OPTIONS (
url " jdbc:sqlite:/customers.db " , dbtable " customer360 "
)
Which line of code fills in the above blank to successfully complete the task?
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company ' s custom-defined network in the cloud. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
A new data engineering team team has been assigned to an ELT project. The new data engineering team will need full privileges on the table sales to fully manage the project.
Which command can be used to grant full permissions on the database to the new data engineering team?
A Data Engineer is building a simple data pipeline using Delta Live Tables (DLT) in Databricksto ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create a DLT pipeline that reads the rawJSON data and writes it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using DLT?
A)

B)

C)

D)

A data engineer is onboarding a new Bronze ingestion pipeline in Databricks with Unity Catalog. The team wants Databricks to handle storage layout, apply platform optimizations over time, and simplify lifecycle management so that when a table is dropped, its underlying data is also cleaned up according to Databricks-managed retention policies.
Which table type should the data engineer create for these ingestion tables?
A data engineer is building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important , but performance and reliable completion of the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
A data engineer needs to apply custom logic to string column city in table stores for a specific use case. In order to apply this custom logic at scale, the data engineer wants to create a SQL user-defined function (UDF).
Which of the following code blocks creates this SQL UDF?
An organization has implemented a data pipeline in Databricks and needs to ensure it can scale automatically based on varying workloads without manual cluster management. The goal is to meet the company’s Service Level Agreements (SLAs), which require high availability and minimal downtime, while Databricks automatically handles resource allocation and optimization.
Which approach fulfills these requirements?
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION DROP ROW
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
Which of the following commands can be used to write data into a Delta table while avoiding the writing of duplicate records?
Which two components function in the DB platform architecture’s control plane? (Choose two.)
A data engineer needs to optimize the data layout and query performance for an e-commerce transactions Delta table. The table is partitioned by " purchase_date " a date column which helps with time-based queries but does not optimize searches on user statistics " customer_id " , a high-cardinality column.
The table is usually queried with filters on " customer_i
d " within specific date ranges, but since this data is spread across multiple files in each partition, it results in full partition scans and increased runtime and costs.
How should the data engineer optimize the Data Layout for efficient reads?




TESTED 06 Jul 2026