You plan to use automated machine learning by using Azure Machine Learning Python SDK v2 to train a regression model. You have data that has features with missing values, and categorical features with few distinct values.
You need to control whether automated machine learning automatically imputes missing values and encode categorical features as part of the training task. Which enemy of the autumn package should you use?
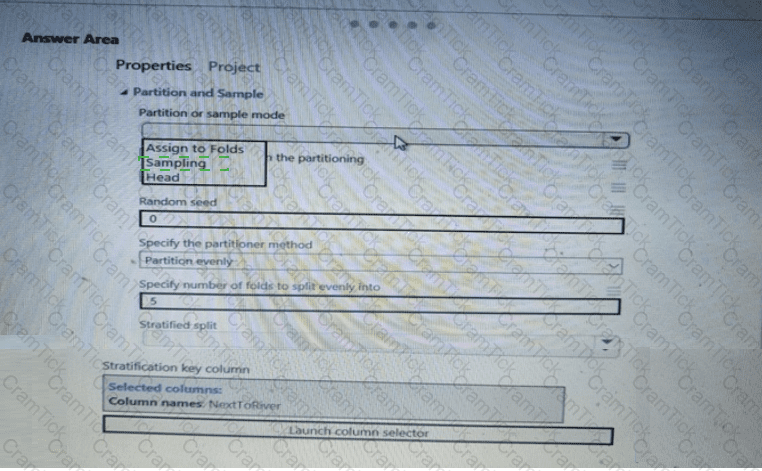
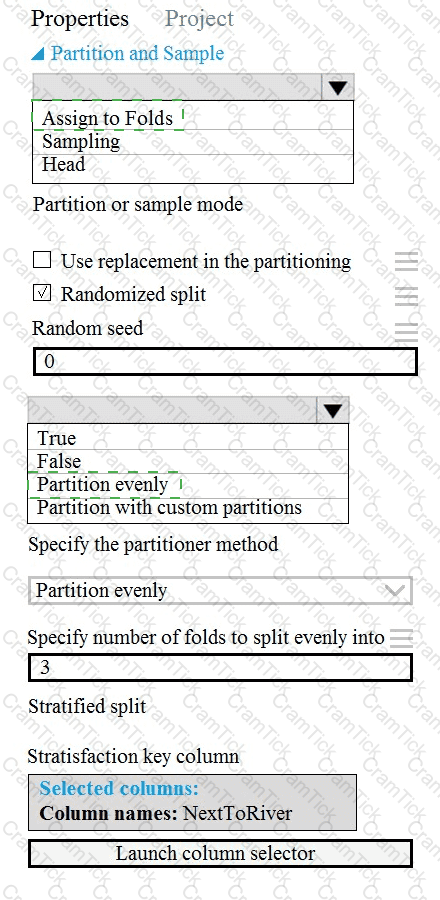
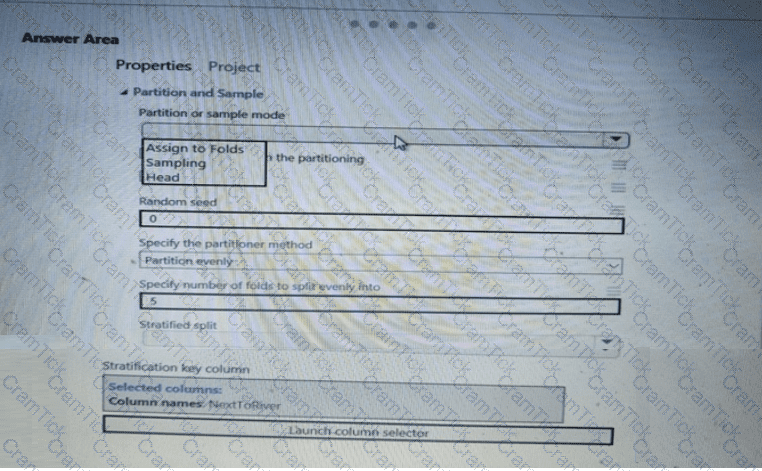
You need to identify the methods for dividing the data according, to the testing requirements.
Which properties should you select? To answer, select the appropriate option-, m the answer area. NOTE: Each correct selection is worth one point.
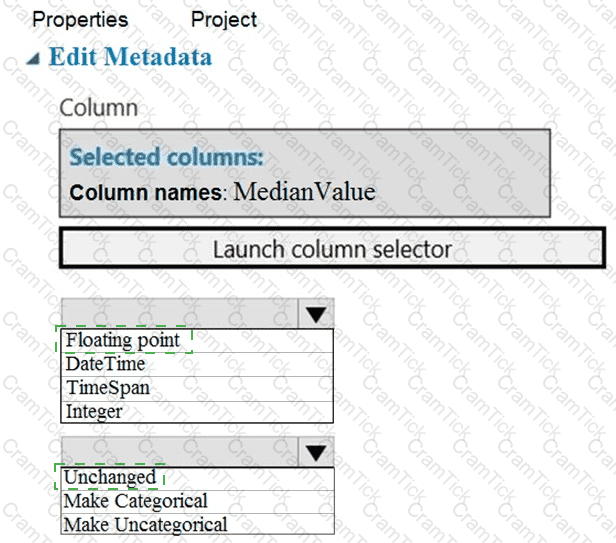
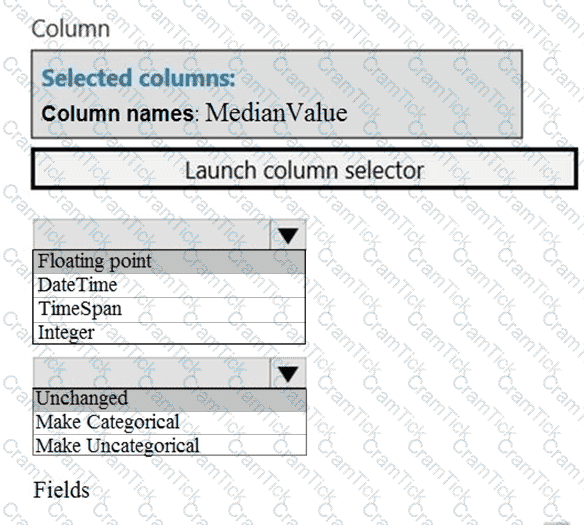
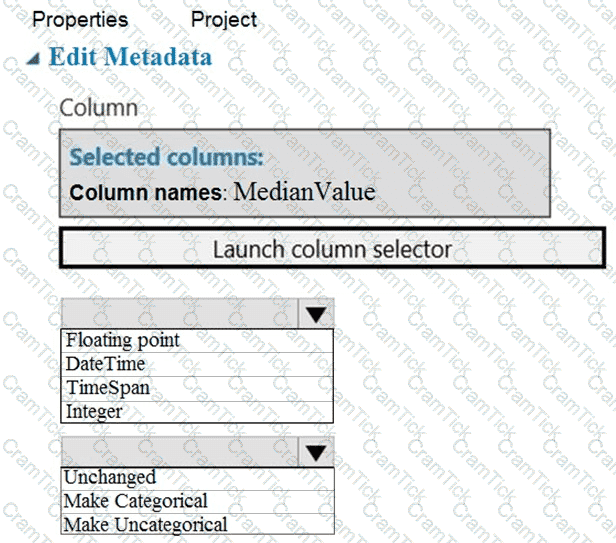
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.

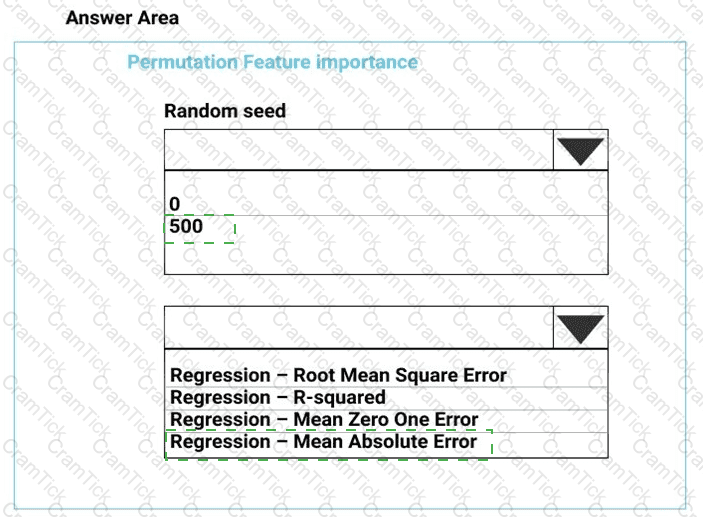
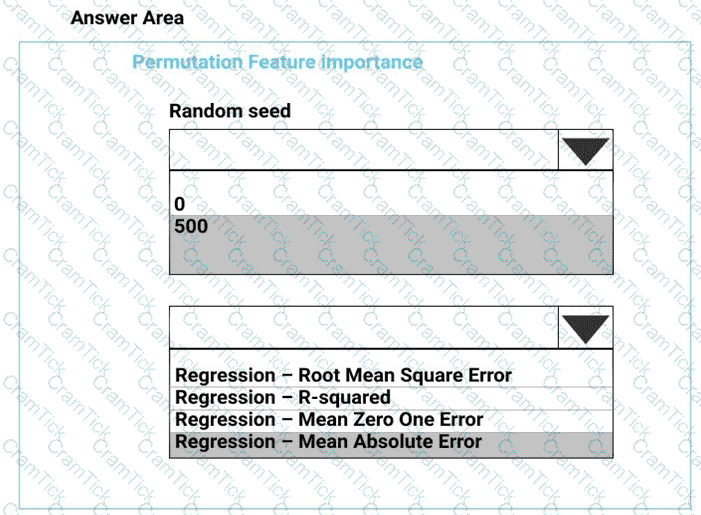
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.

You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

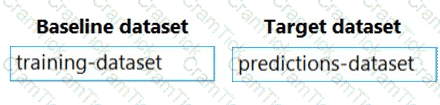
You previously deployed a model that was trained using a tabular dataset named training-dataset, which is based on a folder of CSV files.
Over time, you have collected the features and predicted labels generated by the model in a folder containing a CSV file for each month. You have created two tabular datasets based on the folder containing the inference data: one named predictions-dataset with a schema that matches the training data exactly, including the predicted label; and another named features-dataset with a schema containing all of the feature columns and a timestamp column based on the filename, which includes the day, month, and year.
You need to create a data drift monitor to identify any changing trends in the feature data since the model was trained. To accomplish this, you must define the required datasets for the data drift monitor.
Which datasets should you use to configure the data drift monitor? To answer, drag the appropriate datasets to the correct data drift monitor options. Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You are creating a binary classification by using a two-class logistic regression model.
You need to evaluate the model results for imbalance.
Which evaluation metric should you use?
You ate designing a training job in an Azure Machine Learning workspace by using Automated ML During training, the compute resource must scale up to handle larger datasets. You need to select the compute resource that has a multi-node cluster that automatically scales Which Azure Machine Learning compute target should you use?
You use Azure Machine Learning Designer to load the following datasets into an experiment:
Dataset1
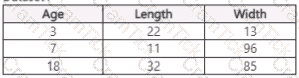
Dataset2
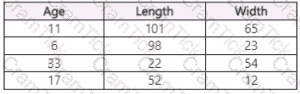
You use Azure Machine Learning Designer to load the following datasets into an experiment:
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Join Data component.
Does the solution meet the goal?
You manage an Azure Machine Learning workspace by using the Python SDK v2.
You must create a compute cluster in the workspace. The compute cluster must run workloads and properly handle interruptions. You start by calculating the maximum amount of compute resources required by the workloads and size the cluster to match the calculations.
The cluster definition includes the following properties and values:
• name= " mlcluster1’’
• size= " STANDARD.DS3.v2 "
• min_instances=1
• maxjnstances=4
• tier= " dedicated "
The cost of the compute resources must be minimized when a workload is active Of idle. Cluster property changes must not affect the maximum amount of compute resources available to the workloads run on the cluster.
You need to modify the cluster properties to minimize the cost of compute resources.
Which properties should you modify? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

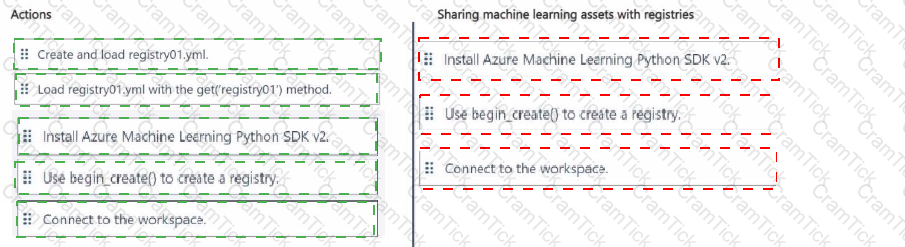
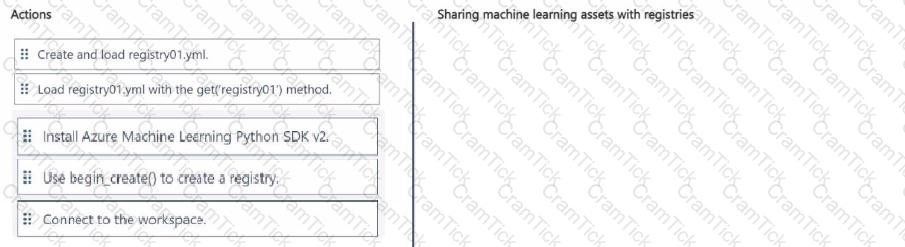
You manage an Azure Machine Learning workspace named workspaces
You plan to create a registry named registry01 with the help of the following registry.yml (line numbers are used for reference only):

You need to use Azure Machine Learning Python SDK v2 with Python 3.10 in a notebook to interact with workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
You manage are Azure Machine Learning workspace by using the Python SDK v2.
You must create an automated machine learning job to generate a classification model by using data files stored in Parquet format. You must configure an auto scaling compute target and a data asset for the job.
You need to configure the resources for the job.
Which resource configuration should you use? to answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

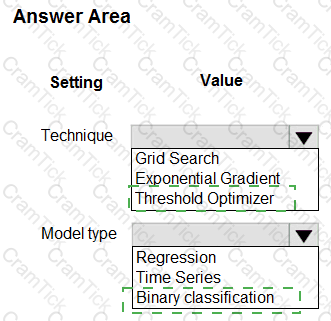
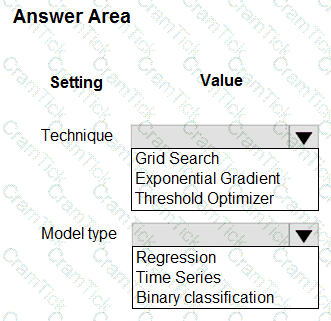
You have machine learning models produce unfair predictions across sensitive features.
You must use a post-processing technique to apply a constraint to the models to mitigate their unfairness.
You need to select a post-processing technique and model type.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a feature set containing the following numerical features: X, Y, and Z.
The Poisson correlation coefficient (r-value) of X, Y, and Z features is shown in the following image:

Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.

You are a data scientist working for a hotel booking website company. You use the Azure Machine Learning service to train a model that identifies fraudulent transactions.
You must deploy the model as an Azure Machine Learning real-time web service using the Model.deploy method in the Azure Machine Learning SDK. The deployed web service must return real-time predictions of fraud based on transaction data input.
You need to create the script that is specified as the entry_script parameter for the InferenceConfig class used to deploy the model.
What should the entry script do?
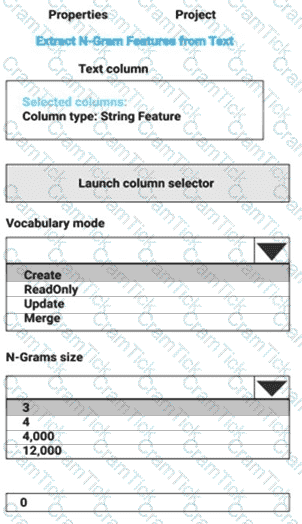
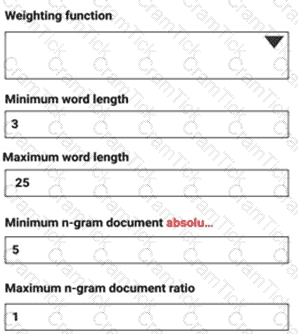
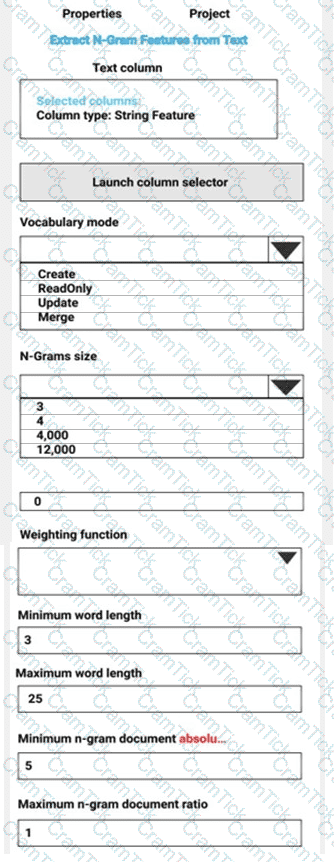
You are performing sentiment analysis using a CSV file that includes 12,000 customer reviews written in a short sentence format. You add the CSV file to Azure Machine Learning Studio and configure it as the starting point dataset of an experiment. You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the customer review column in the dataset.
You must create a new n-gram dictionary from the customer review text and set the maximum n-gram size to trigrams.
What should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
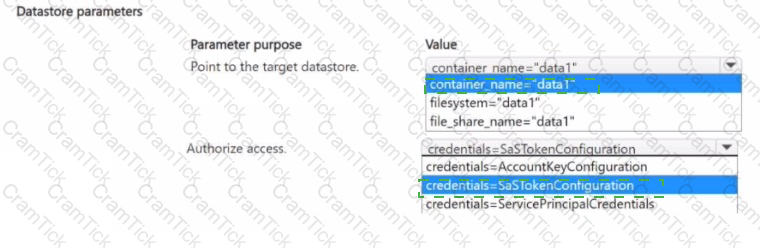
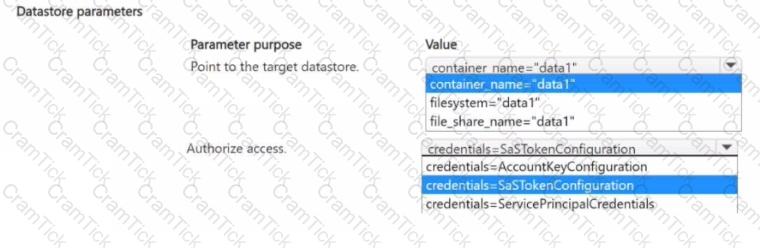
You manage an Azure Machine Learning workspace named Workspace1 and an Azure Blob Storage accessed by using the URL https://storage1.blob.core.wmdows.net/data1.
You plan to create an Azure Blob datastore in Workspace1. The datastore must target the Blob Storage by using Azure Machine Learning Python SDK v2. Access authorization to the datastore must be limited to a specific amount of time.
You need to select the parameters of the Azure Blob Datastore class that will point to the target datastore and authorize access to it.
Which parameters should you use? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.
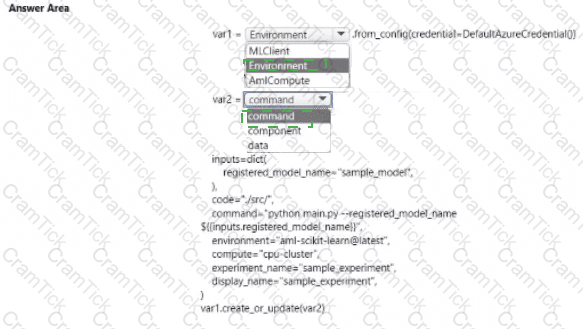
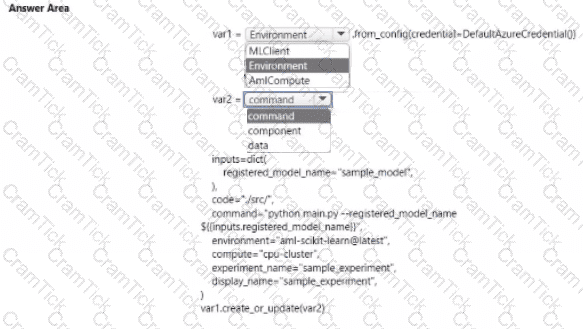
You create an Azure Machine Learning workspace
You are developing a Python SDK v2 notebook to perform custom model training in the workspace. The notebook code imports all required packages.
You need to complete the Python SDK v2 code to include a training script. environment, and compute information.
How should you complete ten code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
You develop and train a machine learning model to predict fraudulent transactions for a hotel booking website.
Traffic to the site varies considerably. The site experiences heavy traffic on Monday and Friday and much lower traffic on other days. Holidays are also high web traffic days. You need to deploy the model as an Azure Machine Learning real-time web service endpoint on compute that can dynamically scale up and down to support demand. Which deployment compute option should you use?
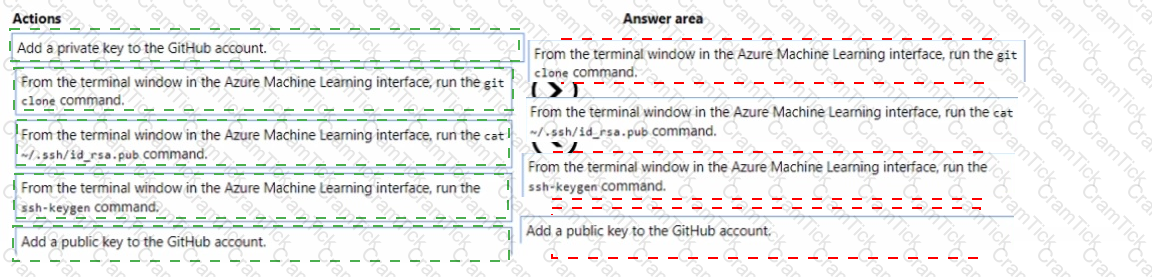
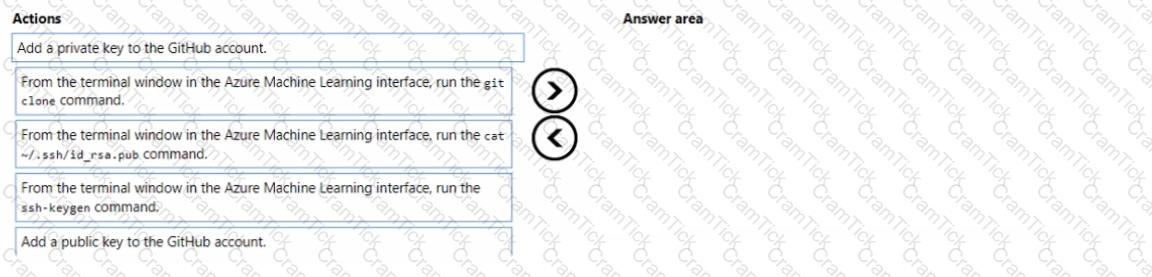
You have an existing GitHub repository containing Azure Machine Learning project files.
You need to clone the repository to your Azure Machine Learning shared workspace file system.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
You have an Azure Machine Learning workspace named WS1.
You plan to use the Responsible Al dashboard to assess MLflow models that you will register in WS1.
You need to identify the library you should use to register the MLflow models.
Which library should you use?
You run an experiment that uses an AutoMLConfig class to define an automated machine learning task with a maximum of ten model training iterations. The task will attempt to find the best performing model based on a metric named accuracy.
You submit the experiment with the following code:
You need to create Python code that returns the best model that is generated by the automated machine learning task. Which code segment should you use?
A)

B)

C)

D)

You manage an Azure Al Foundry project.
You plan to evaluate a fine-tuned large language model by doing the following:
• Identifying discrepancies between runs of the same model to pinpoint the areas where adjustments may be needed.
• Verifying the Al-generated responses align with and are validated by the provided context.
You need to identify an evaluation metric and a comparison feature to assess the performance of the model. Which assessment techniques should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You are planning to register a trained model in an Azure Machine Learning workspace.
You must store additional metadata about the model in a key-value format. You must be able to add new metadata and modify or delete metadata after creation.
You need to register the model.
Which parameter should you use?
You have a multi-class image classification deep learning model that uses a set of labeled photographs. You create the following code to select hyperparameter values when training the model.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You use Azure Machine Learning to train a model based on a dataset named dataset1.
You define a dataset monitor and create a dataset named dataset2 that contains new data.
You need to compare dataset1 and dataset2 by using the Azure Machine Learning SDK for Python.
Which method of the DataDriftDetector class should you use?
You create an Azure Machine Learning workspace named workspaces. You create a Python SDK v2 notebook to perform custom model training in workspace1. You need to run the notebook from Azure Machine Learning Studio in workspace1. What should you provision first?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a model to predict the price of a student’s artwork depending on the following variables: the student’s length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relative Squared Error, and the Coefficient of Determination.
Does the solution meet the goal?
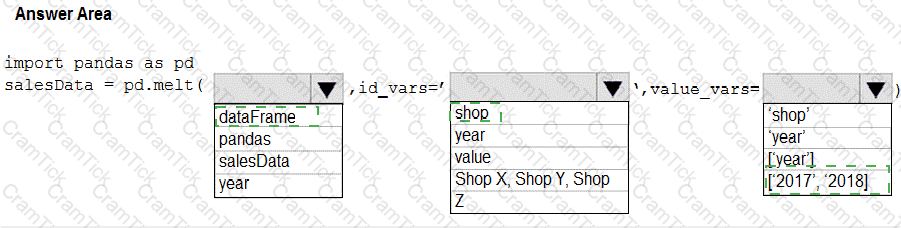
You have a Python data frame named salesData in the following format:
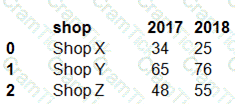
The data frame must be unpivoted to a long data format as follows:
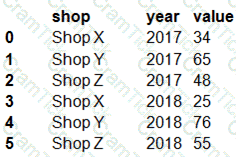
You need to use the pandas.melt() function in Python to perform the transformation.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

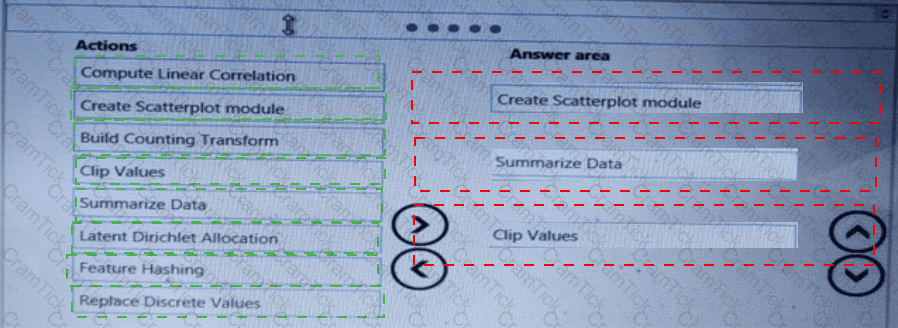
You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

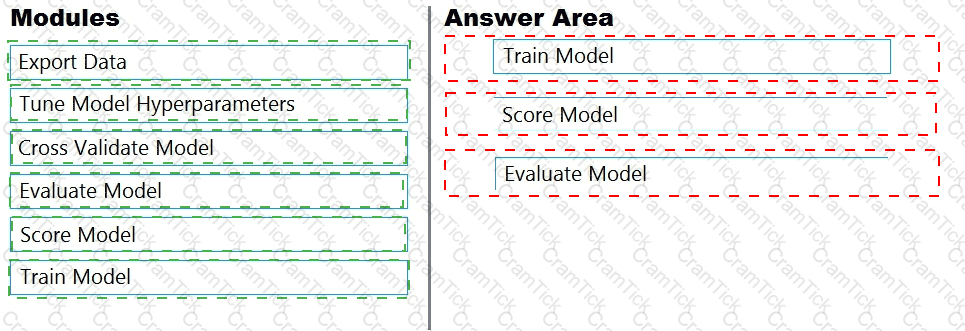
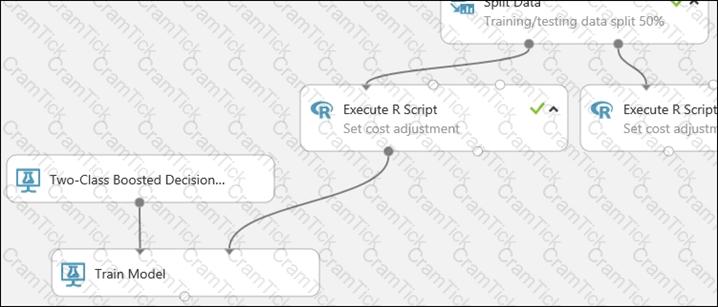
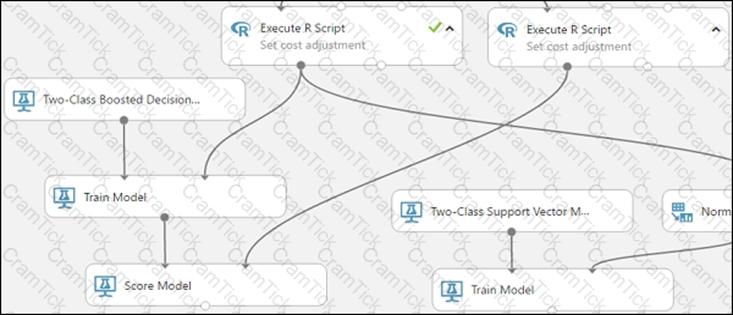
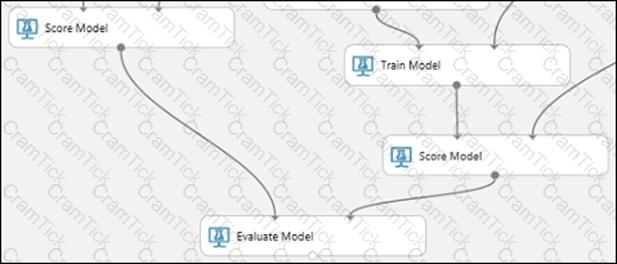
You are building an experiment using the Azure Machine Learning designer.
You split a dataset into training and testing sets. You select the Two-Class Boosted Decision Tree as the algorithm.
You need to determine the Area Under the Curve (AUC) of the model.
Which three modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.
You create an MLflow model
You must deploy the model to Azure Machine Learning for batch inference.
You need to create the batch deployment.
Which two components should you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point
You have fine-tuned an Azure OpenAI Service model by using the Azure Ai Foundry portal. The fine-tuned model is overfitting.
You plan to correct overfitting by fine-tuning the model again
You need to modify the default value of a fine-tuning task parameter to minimize the possibility of overfitting. Which modification should you apply?
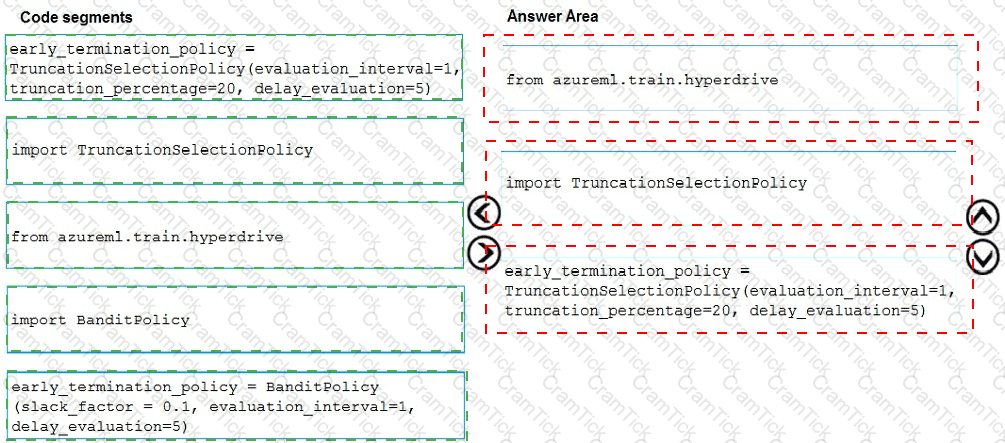
You use Azure Machine Learning to implement hyperparameter tuning with a Bandit early termination policy.
The policy uses a slack_factor set to 01. an evaluation interval set to 1, and an evaluation delay set to b.
You need to evaluate the outcome of the early termination policy
What should you evaluate? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
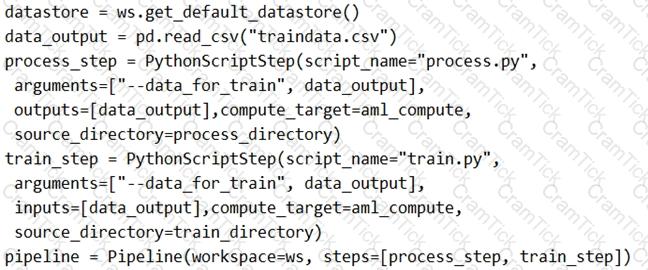
Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:
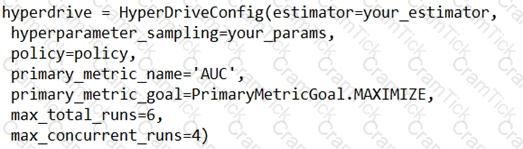
You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted.
You need to add logging to the script to allow Hyperdrive to optimize hyperparameters for the AUC metric.
Solution: Run the following code:

Does the solution meet the goal?
You manage an Azure Machine Learning workspace named workspace!.
You plan to author custom pipeline components by using Azure Machine Learning Python SDK v2.
You must transform the Python code into a YAML specification that can be processed by the pipeline service.
You need to import the Python library that provides the transformation functionality.
Which Python library should you import?
You plan to use automated machine learning to train a regression model. You have data that has features which have missing values, and categorical features with few distinct values.
You need to configure automated machine learning to automatically impute missing values and encode categorical features as part of the training task.
Which parameter and value pair should you use in the AutoMLConfig class?
You manage an Azure At Foundry project. You deploy an Azure OpenAI Service chat model. You configure the development environment with the necessary packages to build a Prompt flow in Visual Studio Code IDE.
You create a Python file called chat.py. You must configure the large language model with 0.2 as the temperature.
You need to develop the chat application.
Which two actions should you perform? Each correct answer presents part of the solution. Choose two.
NOTE: Each correct selection is worth one point.
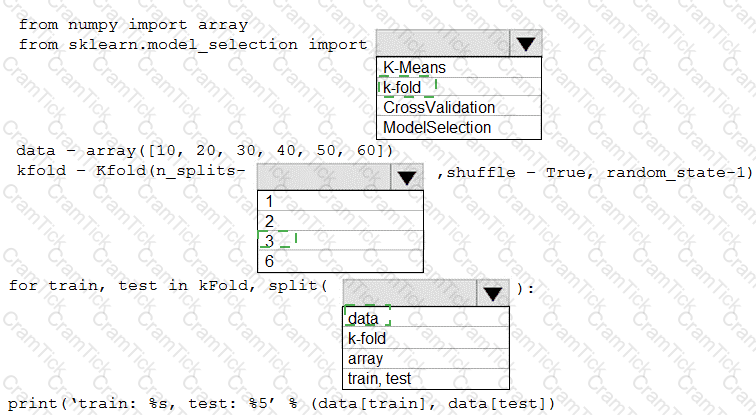
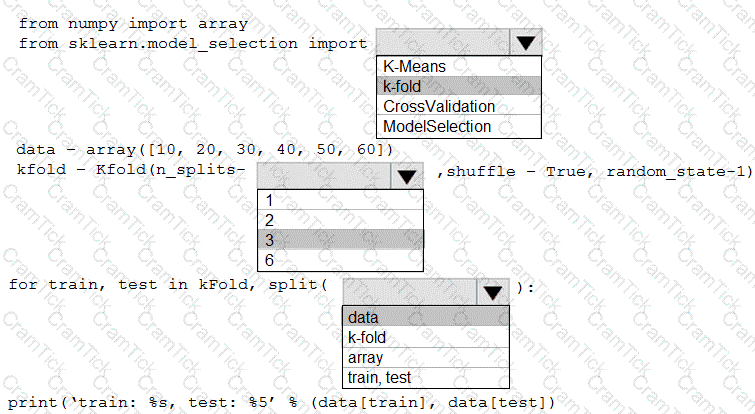
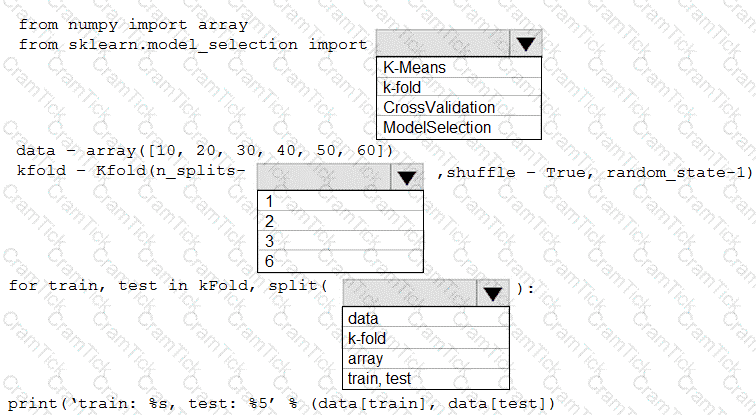
You are evaluating a Python NumPy array that contains six data points defined as follows:
data = [10, 20, 30, 40, 50, 60]
You must generate the following output by using the k-fold algorithm implantation in the Python Scikit-learn machine learning library:
train: [10 40 50 60], test: [20 30]
train: [20 30 40 60], test: [10 50]
train: [10 20 30 50], test: [40 60]
You need to implement a cross-validation to generate the output.
How should you complete the code segment? To answer, select the appropriate code segment in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
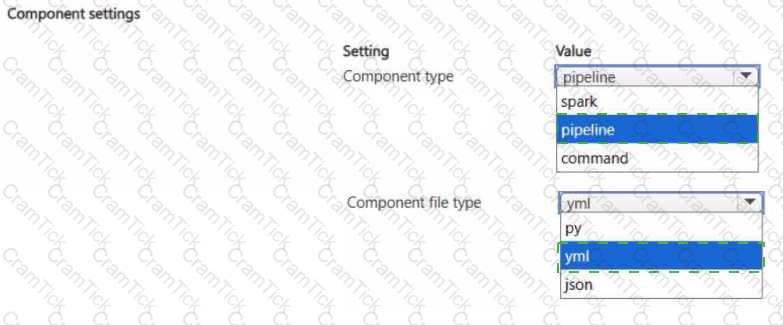
You have an Azure Machine Learning workspace.
You plan to use Azure Machine Learning designer to register multiple components in the workspace.
You need to configure the component that supports the registration.
Which component configuration should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to implement a new cost factor scenario for the ad response models as illustrated in the
performance curve exhibit.
Which technique should you use?
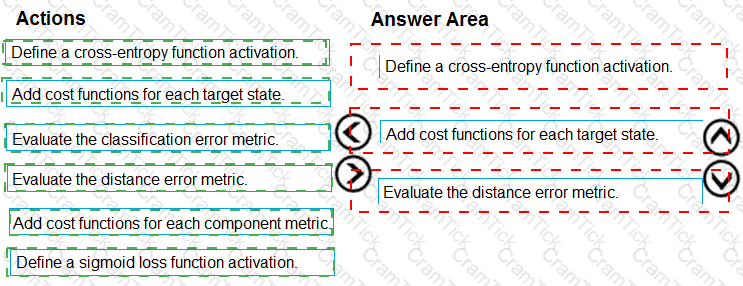
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

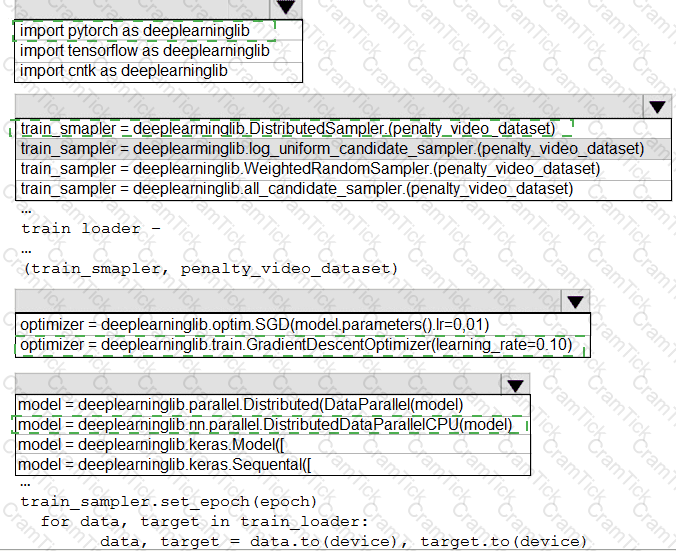
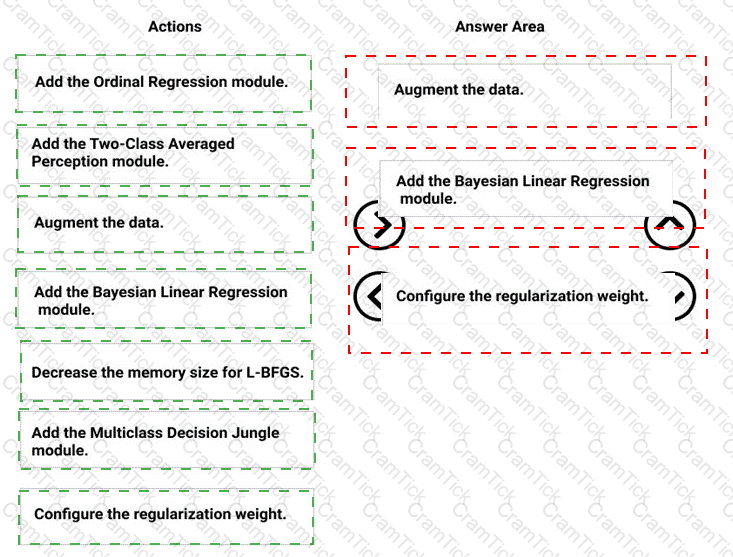
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
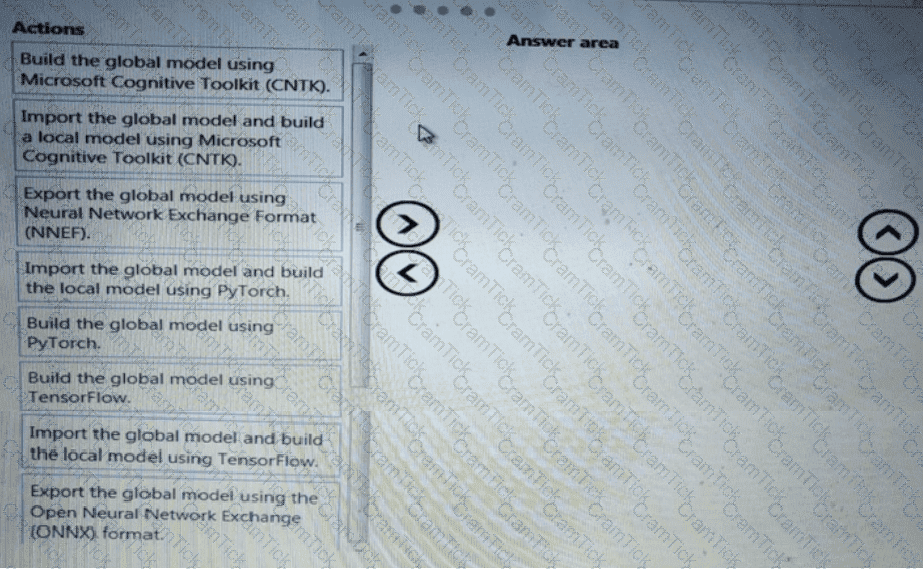
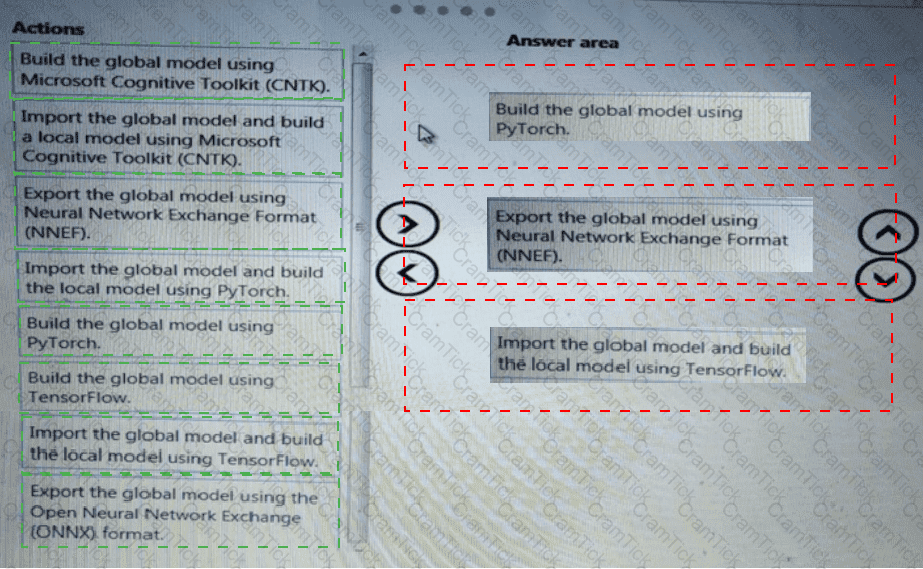
You need to select an environment that will meet the business and data requirements.
Which environment should you use?
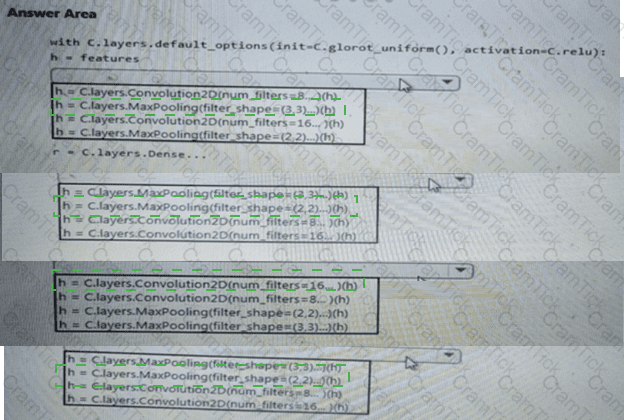
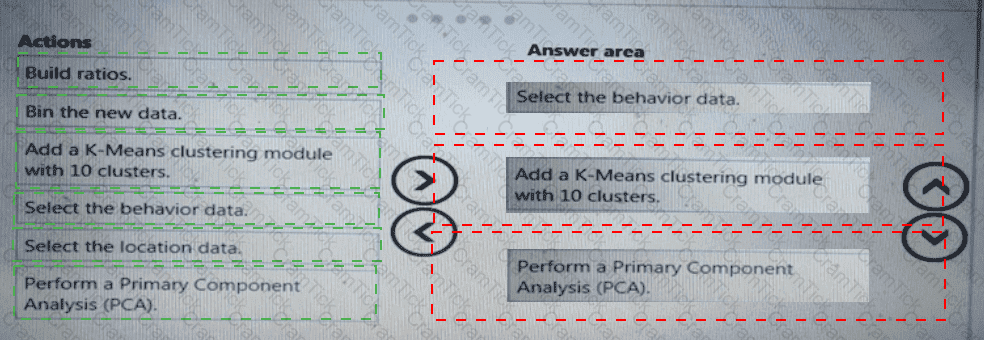
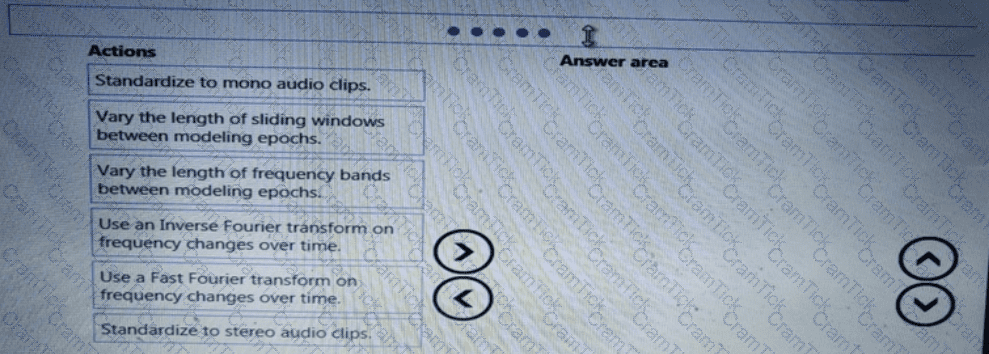
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
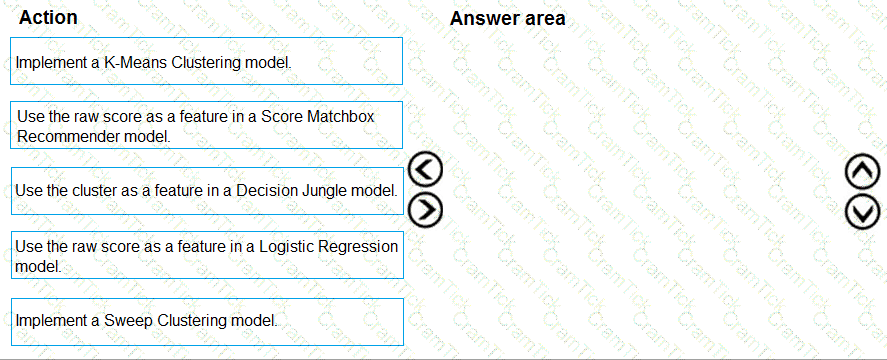
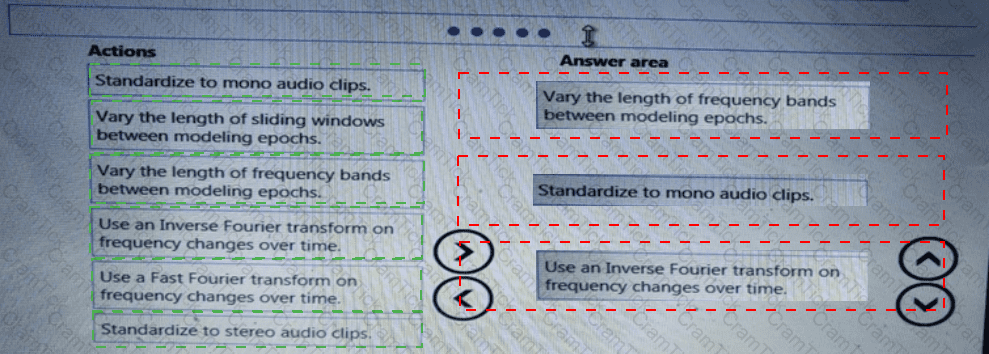
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
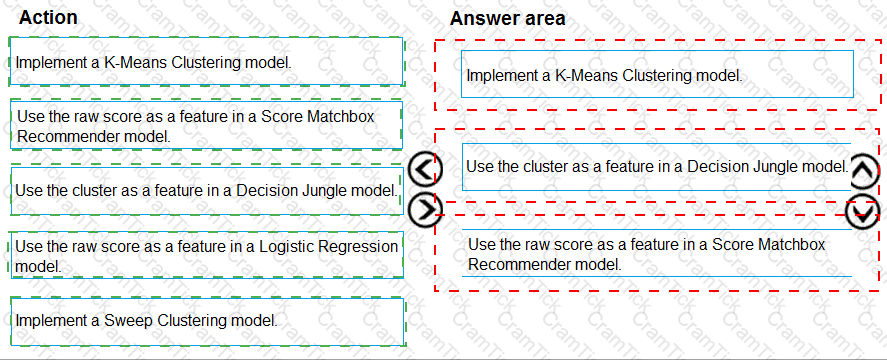
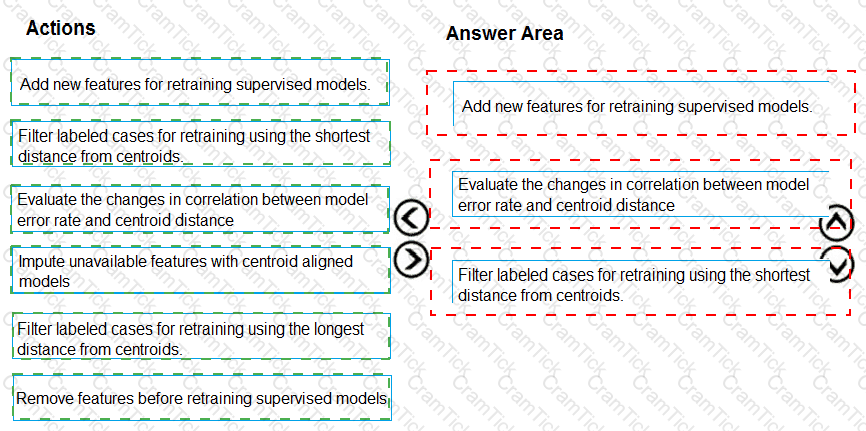
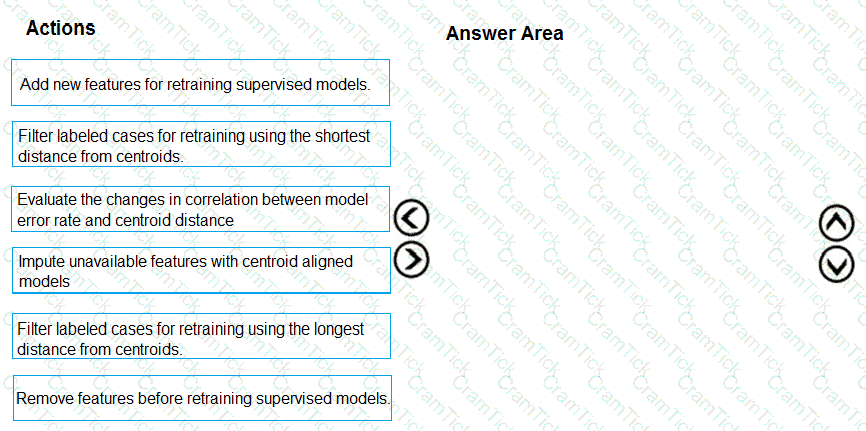
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
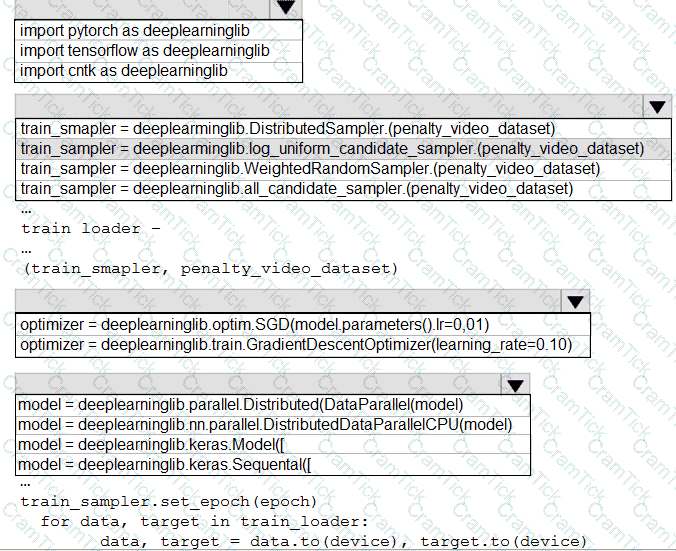
You need to resolve the local machine learning pipeline performance issue. What should you do?
You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use?
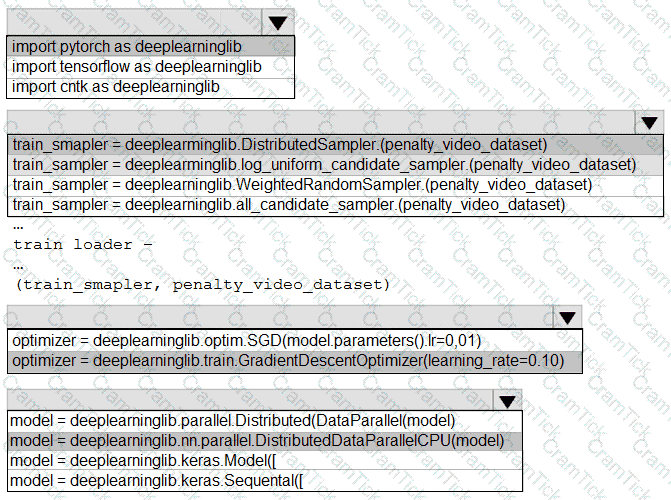
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
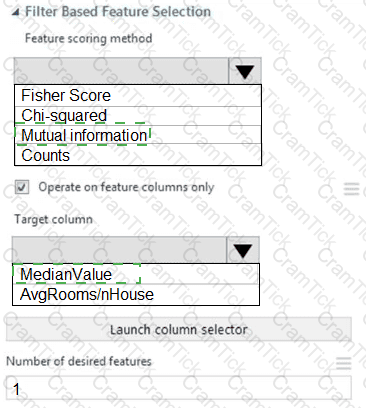
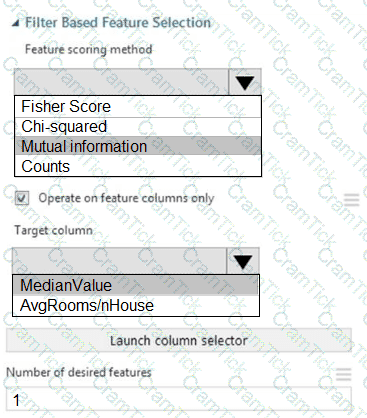
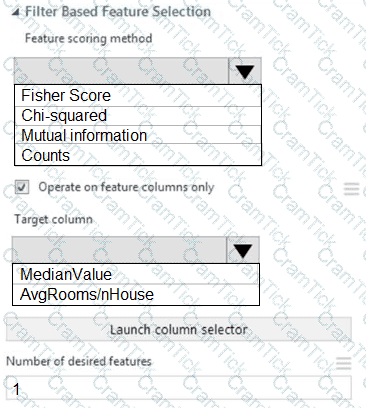
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
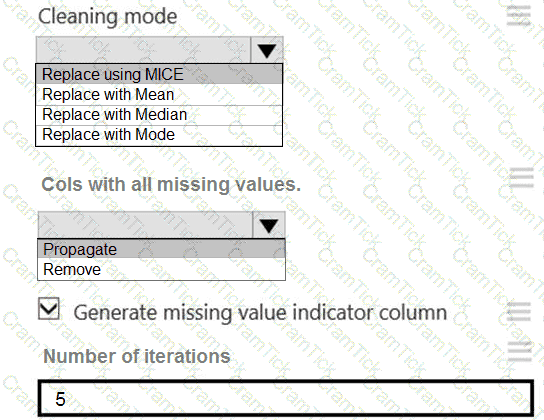
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

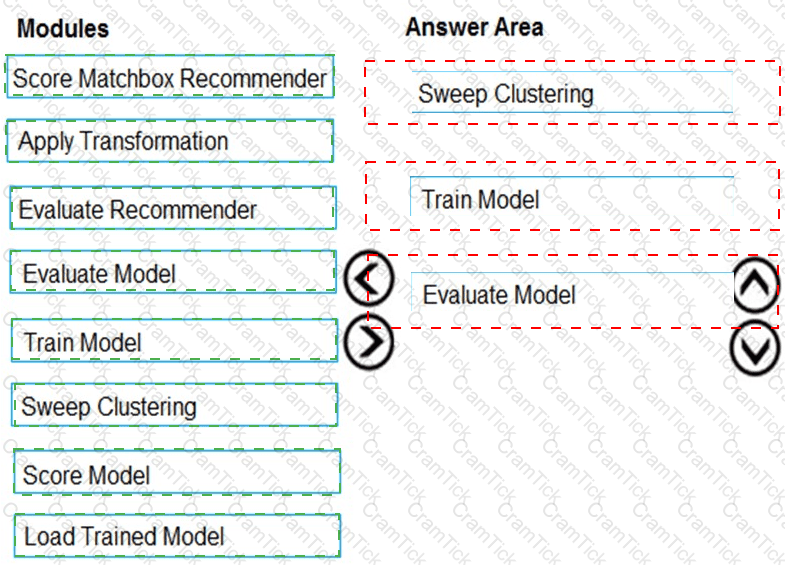
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

Microsoft Azure | DP-100 Exam Topics | DP-100 Questions answers | DP-100 Test Prep | Designing and Implementing a Data Science Solution on Azure Exam Questions PDF | DP-100 Online Exam | DP-100 Practice Test | DP-100 PDF | DP-100 Test Questions | DP-100 Study Material | DP-100 Exam Preparation | DP-100 Valid Dumps | DP-100 Real Questions | Microsoft Azure DP-100 Exam Questions




TESTED 22 Jun 2026