A data engineer wants to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impression led to monitizable clicks.

Which solution would improve the performance?
A)
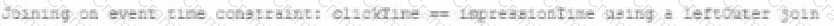
B)

C)
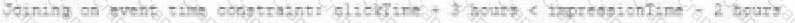
D)

Given the following PySpark code snippet in a Databricks notebook:
filtered_df = spark.read.format( " delta " ).load( " /mnt/data/large_table " ) \
.filter( " event_date > ' 2024-01-01 ' " )
filtered_df.count()
The data engineer notices from the Query Profiler that the scan operator for filtered_df is reading almost all files, despite the filter being applied.
What is the probable reason for poor data skipping?
Spill occurs as a result of executing various wide transformations. However, diagnosing spill requires one to proactively look for key indicators.
Where in the Spark UI are two of the primary indicators that a partition is spilling to disk?
The following table consists of items found in user carts within an e-commerce website.

The following MERGE statement is used to update this table using an updates view, with schema evaluation enabled on this table.

How would the following update be handled?
A workspace admin has created a new catalog called finance_data and wants to delegate permission management to a finance team lead without giving them full admin rights.
Which privilege should be granted to the finance team lead?
A data engineer manages a production Lakeflow Declarative Pipeline that processes customer transaction data. The pipeline includes several data quality expectations such as transaction_amount > 0 and customer_id IS NOT NULL. These expectations are defined using the EXPECT clause in SQL.
The engineer aims to monitor the pipeline’s data quality by analyzing the number of records that passed or failed each expectation during the latest pipeline update. The Lakeflow Declarative Pipelines event logs are stored in a Delta table named event_log_table.
For the most recent pipeline update, determine a programmatically appropriate approach to extract information like the name of each expectation, associated dataset, count of records that passed the expectation, and count of records that failed the expectation.
Which method retrieves the desired data quality metrics from the Lakeflow Declarative Pipelines event log?
A facilities-monitoring team is building a near-real-time PowerBI dashboard off the Delta table device_readings:
Columns:
device_id (STRING, unique sensor ID)
event_ts (TIMESTAMP, ingestion timestamp UTC)
temperature_c (DOUBLE, temperature in °C)
Requirement:
For each sensor, generate one row per non-overlapping 5-minute interval , offset by 2 minutes (e.g., 00:02–00:07, 00:07–00:12, …).
Each row must include interval start, interval end, and average temperature in that slice.
Downstream BI tools (e.g., Power BI) must use the interval timestamps to plot time-series bars.
Options:
A data engineer is optimizing a managed Delta table that suffers from data skew and frequently changing query filter columns . The engineer wants to avoid costly data rewrites when query patterns evolve. The table size is under 1 TB.
How should the data engineer meet this requirement?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df . The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
The business reporting tem requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts transforms and load the data for their pipeline runs in 10 minutes.
Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed. The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all data in the same schema as the source. The next table in the system is named account_current and is implemented as a Type 1 table representing the most recent value for each unique user_id .
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the described account_current table as part of each hourly batch job?
Which Python variable contains a list of directories to be searched when trying to locate required modules?
A data engineer is configuring a pipeline that will potentially see late-arriving, duplicate records.
In addition to de-duplicating records within the batch, which of the following approaches allows the data engineer to deduplicate data against previously processed records as it is inserted into a Delta table?
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by the date variable:

Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
A data engineer is building a Lakeflow Declarative Pipelines pipeline to process healthcare claims data. A metadata JSON file defines data quality rules for multiple tables, including:
{
" claims " : [
{ " name " : " valid_patient_id " , " constraint " : " patient_id IS NOT NULL " },
{ " name " : " non_negative_amount " , " constraint " : " claim_amount > = 0 " }
]
}
The pipeline must dynamically apply these rules to the claims table without hardcoding the rules.
How should the data engineer achieve this?
The data architect has mandated that all tables in the Lakehouse should be configured as external Delta Lake tables.
Which approach will ensure that this requirement is met?
A data engineering team is setting up deployment automation. To deploy workspace assets remotely using the Databricks CLI command, they must configure it with proper authentication.
Which authentication approach will provide the highest level of security ?
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema " customer_id LONG, predictions DOUBLE, date DATE " .

The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
preds.write.mode( " append " ).saveAsTable( " churn_preds " )
preds.write.format( " delta " ).save( " /preds/churn_preds " )
C)

D)

E)

Option A
Option B
Option C
Option D
Option E
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address < > customers.address
) staged_updates
ON customers.customer_id = mergekey
WHEN MATCHED AND customers. current = true AND customers.address < > staged_updates.address THEN
UPDATE SET current = false, end_date = staged_updates.effective_date
WHEN NOT MATCHED THEN
INSERT (customer_id, address, current, effective_date, end_date)
VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null)
Which statement describes this implementation?
The data engineering team maintains the following code:

Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
A data engineer wants to reflector the following DLT code, which includes multiple definition with very similar code:

In an attempt to programmatically create these tables using a parameterized table definition, the data engineer writes the following code.

The pipeline runs an update with this refactored code, but generates a different DAG showing incorrect configuration values for tables.
How can the data engineer fix this?
Given the following error traceback:
AnalysisException: cannot resolve ' heartrateheartrateheartrate ' given input columns:
[spark_catalog.database.table.device_id, spark_catalog.database.table.heartrate,
spark_catalog.database.table.mrn, spark_catalog.database.table.time]
The code snippet was:
display(df.select(3* " heartrate " ))
Which statement describes the error being raised?
A junior developer complains that the code in their notebook isn ' t producing the correct results in the development environment. A shared screenshot reveals that while they ' re using a notebook versioned with Databricks Repos, they ' re using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
The data governance team is reviewing user for deleting records for compliance with GDPR. The following logic has been implemented to propagate deleted requests from the user_lookup table to the user aggregate table.

Assuming that user_id is a unique identifying key and that all users have requested deletion have been removed from the user_lookup table, which statement describes whether successfully executing the above logic guarantees that the records to be deleted from the user_aggregates table are no longer accessible and why?
A data engineer is configuring a Lakeflow Declarative Pipeline to process CDC (Change Data Capture) data from a source. The source events sometimes arrive out of order, and multiple updates may occur with the same update_timestamp but with different update_sequence_id .
What should the data engineer do to ensure events are sequenced correctly?
The data governance team is reviewing code used for deleting records for compliance with GDPR. They note the following logic is used to delete records from the Delta Lake table named users .

Assuming that user_id is a unique identifying key and that delete_requests contains all users that have requested deletion, which statement describes whether successfully executing the above logic guarantees that the records to be deleted are no longer accessible and why?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
To reduce storage and compute costs, the data engineering team has been tasked with curating a series of aggregate tables leveraged by business intelligence dashboards, customer-facing applications, production machine learning models, and ad hoc analytical queries.
The data engineering team has been made aware of new requirements from a customer-facing application, which is the only downstream workload they manage entirely. As a result, an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added.
Which of the solutions addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed?
A data engineer needs to capture pipeline settings from an existing in the workspace, and use them to create and version a JSON file to create a new pipeline.
Which command should the data engineer enter in a web terminal configured with the Databricks CLI?
The data science team has created and logged a production using MLFlow. The model accepts a list of column names and returns a new column of type DOUBLE.
The following code correctly imports the production model, load the customer table containing the customer_id key column into a Dataframe, and defines the feature columns needed for the model.

Which code block will output DataFrame with the schema ' ' customer_id LONG, predictions DOUBLE ' ' ?
Which statement regarding spark configuration on the Databricks platform is true?
A CHECK constraint has been successfully added to the Delta table named activity_details using the following logic:

A batch job is attempting to insert new records to the table, including a record where latitude = 45.50 and longitude = 212.67.
Which statement describes the outcome of this batch insert?
The security team is exploring whether or not the Databricks secrets module can be leveraged for connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password to the secrets module and configure the correct permissions for the currently active user. They then modify their code to the following (leaving all other variables unchanged).

Which statement describes what will happen when the above code is executed?
A data engineer is running a groupBy aggregation on a massive user activity log grouped by user_id. A few users have millions of records, causing task skew and long runtimes.
Which technique will fix the skew in this aggregation?
A data engineer is designing a pipeline in Databricks that processes records from a Kafka stream where late-arriving data is common.
Which approach should the data engineer use?
When scheduling Structured Streaming jobs for production, which configuration automatically recovers from query failures and keeps costs low?
Two data engineers are working on the same Databricks notebook in separate branches. Both have edited the same section of code. When one tries to merge the other’s branch into their own using the Databricks Git folders UI, a merge conflict occurs on that notebook file. The UI highlights the conflict and presents options for resolution.
How should the data engineers resolve this merge conflict using Databricks Git folders?
A healthcare analytics team is implementing a dimensional model in Delta Lake for patient care analysis. They have a date dimension table and are evaluating design options to ensure it supports a wide range of time-based analyses.
Which design approach for the date dimension will support efficient time-based querying and aggregation?
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.

Which statement describes this implementation?
A data engineer is using Lakeflow Declarative Pipelines Expectations feature to track the data quality of their incoming sensor data. Periodically, sensors send bad readings that are out of range, and they are currently flagging those rows with a warning and writing them to the silver table along with the good data. They’ve been given a new requirement – the bad rows need to be quarantined in a separate quarantine table and no longer included in the silver table.
This is the existing code for their silver table:
@dlt.table
@dlt.expect( " valid_sensor_reading " , " reading < 120 " )
def silver_sensor_readings():
return spark.readStream.table( " bronze_sensor_readings " )
What code will satisfy the requirements?
A data engineer wants to ingest a large collection of image files (JPEG and PNG) from cloud object storage into a Unity Catalog–managed table for analysis and visualization.
Which two configurations and practices are recommended to incrementally ingest these images into the table? (Choose 2 answers)
A data engineer is using Lakeflow Declarative Pipeline to propagate row deletions from a source bronze table (user_bronze) to a target silver table (user_silver) . The engineer wants deletions in user_bronze to automatically delete corresponding rows in user_silver during pipeline execution.
Which configuration ensures deletions in the bronze table are propagated to the silver table?
Which statement characterizes the general programming model used by Spark Structured Streaming?
What is a method of installing a Python package scoped at the notebook level to all nodes in the currently active cluster?
A platform engineer is creating catalogs and schemas for the development team to use.
The engineer has created an initial catalog, catalog_A, and initial schema, schema_A. The engineer has also granted USE CATALOG, USE
SCHEMA, and CREATE TABLE to the development team so that the engineer can begin populating the schema with new tables.
Despite being owner of the catalog and schema, the engineer noticed that they do not have access to the underlying tables in Schema_A.
What explains the engineer ' s lack of access to the underlying tables?
A data engineer is using Auto Loader to read incoming JSON data as it arrives. They have configured Auto Loader to quarantine invalid JSON records but notice that over time, some records are being quarantined even though they are well-formed JSON .
The code snippet is:
df = (spark.readStream
.format( " cloudFiles " )
.option( " cloudFiles.format " , " json " )
.option( " badRecordsPath " , " /tmp/somewhere/badRecordsPath " )
.schema( " a int, b int " )
.load( " /Volumes/catalog/schema/raw_data/ " ))
What is the cause of the missing data?
A data team ' s Structured Streaming job is configured to calculate running aggregates for item sales to update a downstream marketing dashboard. The marketing team has introduced a new field to track the number of times this promotion code is used for each item. A junior data engineer suggests updating the existing query as follows: Note that proposed changes are in bold.

Which step must also be completed to put the proposed query into production?
The data engineer is using Spark ' s MEMORY_ONLY storage level.
Which indicators should the data engineer look for in the spark UI ' s Storage tab to signal that a cached table is not performing optimally?
When evaluating the Ganglia Metrics for a given cluster with 3 executor nodes, which indicator would signal proper utilization of the VM ' s resources?
The marketing team is looking to share data in an aggregate table with the sales organization, but the field names used by the teams do not match, and a number of marketing specific fields have not been approval for the sales org.
Which of the following solutions addresses the situation while emphasizing simplicity?
A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE
This table is partitioned by the date column. A query is run with the following filter:
longitude < 20 and longitude > -20
Which statement describes how data will be filtered?
A junior data engineer has manually configured a series of jobs using the Databricks Jobs UI. Upon reviewing their work, the engineer realizes that they are listed as the " Owner " for each job. They attempt to transfer " Owner " privileges to the " DevOps " group, but cannot successfully accomplish this task.
Which statement explains what is preventing this privilege transfer?
A nightly job ingests data into a Delta Lake table using the following code:

The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
def new_records():
return spark.readStream.table( " bronze " )
return spark.readStream.load( " bronze " )

return spark.read.option( " readChangeFeed " , " true " ).table ( " bronze " )

A data engineer is designing a system to process batch patient encounter data stored in an S3 bucket, creating a Delta table (patient_encounters) with columns encounter_id, patient_id, encounter_date, diagnosis_code, and treatment_cost. The table is queried frequently by patient_id and encounter_date, requiring fast performance. Fine-grained access controls must be enforced. The engineer wants to minimize maintenance and boost performance.
How should the data engineer create the patient_encounters table?
A data engineer is designing a Lakeflow Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id and amount are greater than zero. Invalid records should be dropped.
Which Lakeflow Declarative Pipelines configurations implement this requirement using Python?
A data organization has adopted Delta Sharing to securely distribute curated datasets from a Unity Catalog-enabled workspace . The data engineering team shares large Delta tables internally via Databricks-to-Databricks and externally via Open Sharing for aggregated reports. While testing, they encounter challenges related to access control, data update visibility, and shareable object types.
What is a limitation of the Delta Sharing protocol or implementation when used with Databricks-to-Databricks or Open Sharing?




TESTED 06 Jul 2026