A data scientist wants to evaluate the performance of various nonlinear models. Which of the following is best suited for this task?
Which of the following measures would a data scientist most likely use to calculate the similarity of two text strings?
A data scientist is deploying a model that needs to be accessed by multiple departments with minimal development effort by the departments. Which of the following APIs would be best for the data scientist to use?
A data analyst is analyzing data and would like to build conceptual associations. Which of the following is the best way to accomplish this task?
A data scientist wants to digitize historical hard copies of documents. Which of the following is the best method for this task?
A data scientist is clustering a data set but does not want to specify the number of clusters present. Which of the following algorithms should the data scientist use?
A data scientist is building a proof of concept for a commercialized machine-learning model. Which of the following is the best starting point?
During EDA, a data scientist wants to look for patterns, such as linearity, in the data. Which of the following plots should the data scientist use?
A statistician notices gaps in data associated with age-related illnesses and wants to further aggregate these observations. Which of the following is the best technique to achieve this goal?
A data scientist has built an image recognition model that distinguishes cars from trucks. The data scientist now wants to measure the rate at which the model correctly identifies a car as a car versus when it misidentifies a truck as a car. Which of the following would best convey this information?
Which of the following issues should a data scientist be most concerned about when generating a synthetic data set?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?
Which of the following modeling tools is appropriate for solving a scheduling problem?
Which of the following is the layer that is responsible for the depth in deep learning?
Which of the following layer sets includes the minimum three layers required to constitute an artificial neural network?
A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
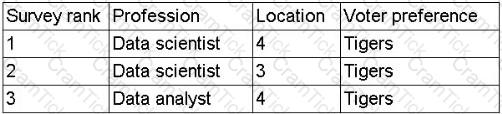
(Screenshot shows survey rankings for just two professions and a few locations, all voting for "Tigers")
Which of the following is the most likely concern about the model's ability to predict the outcome of the vote?
A data scientist wants to predict a person's travel destination. The options are:
Branson, Missouri, United States
Mount Kilimanjaro, Tanzania
Disneyland Paris, Paris, France
Sydney Opera House, Sydney, Australia
Which of the following models would best fit this use case?
A data analyst wants to use compression on an analyzed data set and send it to a new destination for further processing. Which of the following issues will most likely occur?
A data scientist is building an inferential model with a single predictor variable. A scatter plot of the independent variable against the real-number dependent variable shows a strong relationship between them. The predictor variable is normally distributed with very few outliers. Which of the following algorithms is the best fit for this model, given the data scientist wants the model to be easily interpreted?
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?

TESTED 07 Jul 2026


