Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
A company is developing a merchandise sales application The product team uses training data to teach the AI model predicting sales, and discovers emergent bias. What caused the biased results?
Which of the following describes a neural network without an activation function?
Which of the following sentences is true about model evaluation and model validation in ML pipelines?
Which of the following statements are true regarding highly interpretable models? (Select two.)
A dataset can contain a range of values that depict a certain characteristic, such as grades on tests in a class during the semester. A specific student has so far received the following grades: 76,81, 78, 87, 75, and 72. There is one final test in the semester. What minimum grade would the student need to achieve on the last test to get an 80% average?
Which of the following unsupervised learning models can a bank use for fraud detection?
In addition to understanding model performance, what does continuous monitoring of bias and variance help ML engineers to do?
Which of the following can benefit from deploying a deep learning model as an embedded model on edge devices?
Which of the following describes a benefit of machine learning for solving business problems?
For a particular classification problem, you are tasked with determining the best algorithm among SVM, random forest, K-nearest neighbors, and a deep neural network. Each of the algorithms has similar accuracy on your data. The stakeholders indicate that they need a model that can convey each feature's relative contribution to the model's accuracy. Which is the best algorithm for this use case?
Personal data should not be disclosed, made available, or otherwise used for purposes other than specified with which of the following exceptions? (Select two.)
You create a prediction model with 96% accuracy. While the model's true positive rate (TPR) is performing well at 99%, the true negative rate (TNR) is only 50%. Your supervisor tells you that the TNR needs to be higher, even if it decreases the TPR. Upon further inspection, you notice that the vast majority of your data is truly positive.
What method could help address your issue?
Your dependent variable Y is a count, ranging from 0 to infinity. Because Y is approximately log-normally distributed, you decide to log-transform the data prior to performing a linear regression.
What should you do before log-transforming Y?
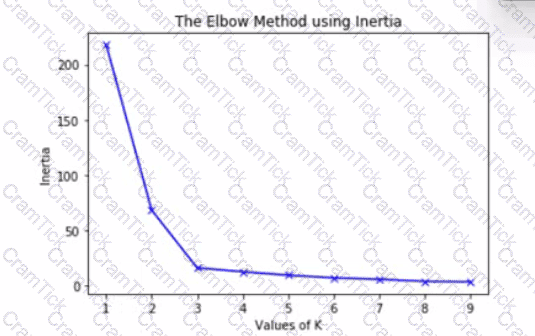
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Which of the following regressions will help when there is the existence of near-linear relationships among the independent variables (collinearity)?
We are using the k-nearest neighbors algorithm to classify the new data points. The features are on different scales.
Which method can help us to solve this problem?
Which type of regression represents the following formula: y = c + b*x, where y = estimated dependent variable score, c = constant, b = regression coefficient, and x = score on the independent variable?
Which two of the following decrease technical debt in ML systems? (Select two.)
You are implementing a support-vector machine on your data, and a colleague suggests you use a polynomial kernel. In what situation might this help improve the prediction of your model?




TESTED 06 Jul 2026