Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
A developer is working with a pandas DataFrame containing user behavior data from a web application.
Which approach should be used for executing a groupBy operation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)

C)

D)

A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
31 of 55.
Given a DataFrame df that has 10 partitions, after running the code:
df.repartition(20)
How many partitions will the result DataFrame have?
A data engineer wants to create a Streaming DataFrame that reads from a Kafka topic called feed.

Which code fragment should be inserted in line 5 to meet the requirement?
Code context:
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.[LINE 5] \
.load()
Options:
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)

D)

Which code fragment should be inserted to meet the requirement?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
6 of 55.
Which components of Apache Spark’s Architecture are responsible for carrying out tasks when assigned to them?
A data scientist is analyzing a large dataset and has written a PySpark script that includes several transformations and actions on a DataFrame. The script ends with a collect() action to retrieve the results.
How does Apache Spark™'s execution hierarchy process the operations when the data scientist runs this script?
A data engineer wants to create an external table from a JSON file located at /data/input.json with the following requirements:
Create an external table named users
Automatically infer schema
Merge records with differing schemas
Which code snippet should the engineer use?
Options:
26 of 55.
A data scientist at an e-commerce company is working with user data obtained from its subscriber database and has stored the data in a DataFrame df_user.
Before further processing, the data scientist wants to create another DataFrame df_user_non_pii and store only the non-PII columns.
The PII columns in df_user are name, email, and birthdate.
Which code snippet can be used to meet this requirement?
24 of 55.
Which code should be used to display the schema of the Parquet file stored in the location events.parquet?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columns sensor_id, temperature, and timestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)

B)

C)

D)
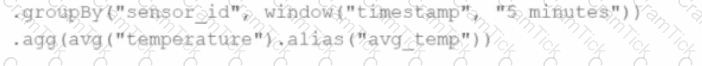
A data analyst builds a Spark application to analyze finance data and performs the following operations: filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A data engineer observes that an upstream streaming source sends duplicate records, where duplicates share the same key and have at most a 30-minute difference in event_timestamp. The engineer adds:
dropDuplicatesWithinWatermark("event_timestamp", "30 minutes")
What is the result?
A data scientist wants each record in the DataFrame to contain:
The first attempt at the code does read the text files but each record contains a single line. This code is shown below:

The entire contents of a file
The full file path
The issue: reading line-by-line rather than full text per file.
Code:
corpus = spark.read.text("/datasets/raw_txt/*") \
.select('*', '_metadata.file_path')
Which change will ensure one record per file?
Options:
22 of 55.
A Spark application needs to read multiple Parquet files from a directory where the files have differing but compatible schemas.
The data engineer wants to create a DataFrame that includes all columns from all files.
Which code should the data engineer use to read the Parquet files and include all columns using Apache Spark?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
A data engineer uses a broadcast variable to share a DataFrame containing millions of rows across executors for lookup purposes. What will be the outcome?
Given the following code snippet in my_spark_app.py:

What is the role of the driver node?
47 of 55.
A data engineer has written the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv")
df2 = spark.read.csv("product_data.csv")
df_joined = df1.join(df2, df1.product_id == df2.product_id)
The DataFrame df1 contains ~10 GB of sales data, and df2 contains ~8 MB of product data.
Which join strategy will Spark use?
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:

The resulting Python dictionary must contain a mapping of region -> region id containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A)

B)

C)

D)

The resulting Python dictionary must contain a mapping of region -> region_id for the smallest 3 region_id values.
Which code fragment meets the requirements?
Given this code:

.withWatermark("event_time", "10 minutes")
.groupBy(window("event_time", "15 minutes"))
.count()
What happens to data that arrives after the watermark threshold?
Options:
Which feature of Spark Connect is considered when designing an application to enable remote interaction with the Spark cluster?
An engineer wants to join two DataFrames df1 and df2 on the respective employee_id and emp_id columns:
df1: employee_id INT, name STRING
df2: emp_id INT, department STRING
The engineer uses:
result = df1.join(df2, df1.employee_id == df2.emp_id, how='inner')
What is the behaviour of the code snippet?
An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
17 of 55.
A data engineer has noticed that upgrading the Spark version in their applications from Spark 3.0 to Spark 3.5 has improved the runtime of some scheduled Spark applications.
Looking further, the data engineer realizes that Adaptive Query Execution (AQE) is now enabled.
Which operation should AQE be implementing to automatically improve the Spark application performance?
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?




TESTED 17 Jul 2026